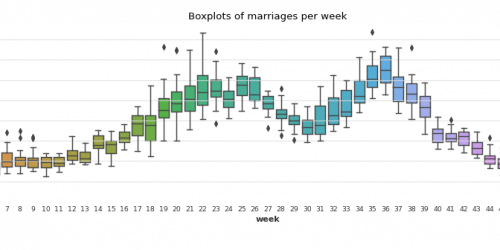
In this blog we use timeseries analyses to model the trend in Dutch marriages and extrapolate this to the first two Covid-19 years (2020 and 2021). Doing so we are able to shed some light on the expected amount of marriages postponed, and what might be ahead of us in 2022, of course dependent on local restrictions next year. We use public available data provided by Statistics Netherlands on the number of marriages in past years.

How to uncover the predictive potential of textual data using topic modeling, word embedding, transfer learning and transformer models with R Textual data is everywhere: reviews, customer questions, log files, books, transcripts, news articles, files, interview reports … Yet, texts are still (too) little involved in answering analysis questions, in addition to available structured data. […]

In a sequence of articles we compare different NLP techniques to show you how we get valuable information from unstructured text. About a year ago we gathered reviews on Dutch restaurants. We were wondering whether ’the wisdom of the croud’ – reviews from restaurant visitors – could be used to predict which restaurants are most likely to receive a new Michelin-star. Read this post to see how that worked out. We used topic modeling as our primary tool to extract information from the review texts and combined that with predictive modeling techniques to end up with our predictions.
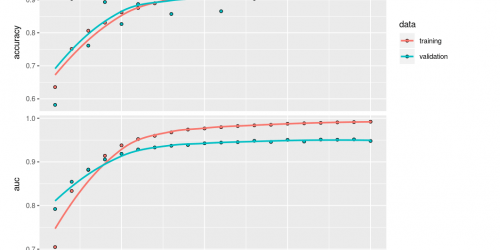
We got a lot of attention with our predictions and also questions about how we did the text analysis part. To answer these questions, we explain our approach in more detail in a series of articles on NLP. We didn’t stop exploring NLP techniques after our publication, and we also like to share insights from adding more novel NLP techniques. More specifically we will use two types of word embeddings – a classic Word2Vec model and a GLoVe embedding model – we’ll use transfer learning with pretrained word embeddings and we use transformers like BERT. We compare the added value of these advanced NLP techniques to our baseline topic model on the same dataset. By showing what we did and how we did it, we hope to guide others that are keen to use textual data for their own data science endeavours.
In a sequence of articles we compare different NLP techniques to show you how we get valuable information from unstructured text. About a year ago we gathered reviews on Dutch restaurants. We were wondering whether ’the wisdom of the croud’ – reviews from restaurant visitors – could be used to predict which restaurants are most likely to receive a new Michelin-star. Read this post to see how that worked out. We used topic modeling as our primary tool to extract information from the review texts and combined that with predictive modeling techniques to end up with our predictions.
We got a lot of attention with our predictions and also questions about how we did the text analysis part. To answer these questions, we explain our approach in more detail in a series of articles on NLP. But we didn’t stop exploring NLP techniques after our publication, and we also like to share insights from adding more novel NLP techniques. More specifically we will use two types of word embeddings – a classic Word2Vec model and a GLoVe embedding model – we’ll use transfer learning with pretrained word embeddings and we use BERT. We compare the added value of these advanced NLP techniques to our baseline topic model on the same dataset. By showing what we did and how we did it, we hope to guide others that are keen to use textual data for their own data science endeavours.
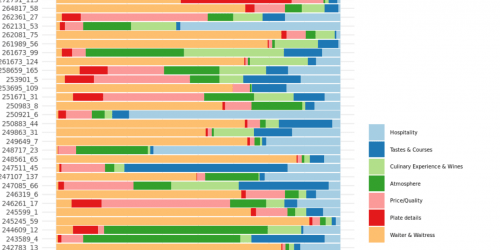
n a sequence of articles we compare different NLP techniques to show you how we get valuable information from unstructured text. About a year ago we gathered reviews on Dutch restaurants. We were wondering whether ’the wisdom of the croud’ – reviews from restaurant visitors – could be used to predict which restaurants are most likely to receive a new Michelin-star. Read this post to see how that worked out. We used topic modeling as our primary tool to extract information from the review texts and combined that with predictive modeling techniques to end up with our predictions.
We got a lot of attention with our predictions and also questions about how we did the text analysis part. To answer these questions, we explain our approach in more detail in a series of articles on NLP. But we didn’t stop exploring NLP techniques after our publication, and we also like to share insights from adding more novel NLP techniques. More specifically we will use two types of word embeddings – a classic Word2Vec model and a GLoVe embedding model – we’ll use transfer learning with pretrained word embeddings and we use BERT. We compare the added value of these advanced NLP techniques to our baseline topic model on the same dataset. By showing what we did and how we did it, we hope to guide others that are keen to use textual data for their own data science endeavours.

Op vrijdag 10 maart jl. heeft de tweede “The Analytics Lab Hackathon” plaatsgevonden, de opdracht was dit keer om de zetelverdeling te voorspellen van de Tweede Kamer na de verkiezingen van 15 maart. Dankzij de serieuze, sportieve en ook humoristische inzet van onze deelnemende teams is het weer een zeer leuke dag geweest, waarbij iedereen […]