Data to predict which employees are likely to leave
Geplaatst op: februari 24, 2022

series: NO DATA SCIENTIST IS THE SAME! – part 2
All Python notebooks from this series are available on our Gitlab page.





Introducing our Data Science Rock Stars
Geplaatst op: februari 24, 2022

series: NO DATA SCIENTIST IS THE SAME! – part 1
All Python notebooks from this series are available on our Gitlab page.
Save any type of file from Azure Synapse Notebook on Azure Data Lake Gen2
Geplaatst op: februari 9, 2022

If you are more a Data Scientist than a Data Engineer, you’ve just started working in Azure Synapse Analytics Studio and you feel lost and frustrated every now and again, I feel you and I’m here for you. I can only hope you are as lucky as I am, having some very skilled Data Engineering colleagues (my heroes: Henrik Reich, Farzad Bonabi & Ernst Bolle). Without them I would feel completely lost.
Even though there is a whole lot to love when it comes to Azure Synapse Analytics Studio, some should-have-been-easy tasks can cause a lot of question marks and frustration. One of those tasks, for me, was how to save a graph created in a notebook as a png file on the Azure Data Lake Generation 2 (abfss location). Which, in our Azure Synapse, is located here:

I’ve done a fair share of googling, all very unnecessary as I should have just run to my Data Engineering colleagues, who were there to save the/my day again. Of course, as expected, this task was very easy after all. It’s always easy when you know how to do it, isn’t it?
For my fellow Data Scientists, who are either a bit too independent like me, or simply don’t have any Data Engineering colleagues at hand, this short article shows you the very few lines of code needed to use plt.savefig (or any method like this one) to save your graph as a png file on an Azure Data Lake Gen 2 from our Azure Synapse Analytics Studio Notebook.
Or, to make it a bit more general, how to save a file from a Synapse Notebook on a Data Lake Gen 2, using a non-spark kind of Python package. But for this example, I’ll show it using matplotlibs savefig function.
The Python code
import matplotlib.pyplot as plt
# before we can save, for instance, figures in our workspace (or other location) on the Data Lake Gen 2 we need to mount this location in our notebook
# there is no harm in running this cell multiple times
# we need to define the linked service, which for me is Workspaces
# and the name of the workspace, which for me is my own name
mssparkutils.fs.unmount('/jeanineschoonemann)
mssparkutils.fs.mount("abfss://jeanineschoonemann@cldidevdpdsws.dfs.core.windows.net", "/jeanineschoonemann ", {"linkedService":"Workspaces"})
# we’re good to go now already! I told you it was simple :)
# create a sample plot, using some sample data
plt.plot([0, 1, 2, 3, 4], [0, 3, 5, 9, 11])
plt.xlabel('Months')
plt.ylabel('Books Read')
plt.show()
# retrieve the job-id from the Spark environment
jobId = mssparkutils.env.getJobId()
# now save the image as a png file to the location we've mounted before
plt.savefig(f"/synfs/{jobId}/jeanineschoonemann/mybookfolder/books.png")

What we Learned from Kaggle’s CommonLit Readability Prize
Geplaatst op: september 6, 2021

At Cmotions, we love a challenge. Especially those that make us both think and have fun. Every now and then we start a so-called ‘Project-Friday’ where we combine data science with a fun project. In the past we build a coffee machine with visibility, an algorithm for handsign recognition, a book recommender and a PowerBI escaperoom. A few months ago, we decided to join a Kaggle competition: the CommonLit Readability, for numerous reasons. First of all, for many of us this is the first time attending a Kaggle competition; high on many bucket lists. Not to mention we like to do more with textual data to get a deeper knowledge of NLP techniques. And last but not least, we like to help kids to read stuff that meet their profile.
In the CommonLit competition this question needs to be answered:
“To what extent can machine learning identify the appropriate reading level of a passage of text, and help inspire learning?”
This question arose as CommonLit, Inc. and Georgia State University wanted to offer texts of the right level of challenge to 3rd to 12th grade students, in order to stimulate the natural development of their reading skills. Until now, the readability of (English) texts, has been based mainly on expert assessments, or on well-known formulas, such as the Flesch-Kincaid Grade Level, which often lack construct and theoretical validity. Other, often commercial solutions also failed to meet the proof and transparency requirements.
To win a Kaggle competition…
Before we entered the competition, we did see some drawbacks. Often, a high rank in a Kaggle competition these days means combining many, many, many models to gain a bit of precision and a lot of rank positions – there’s not a lot of difference in accuracy in the highest ranked contenders. With the increase of predictive performance there’s a steep decrease in interpretability when combining the results of many models into a final prediction. Also, since this challenge is about textual data and we do not have many train cases, state of the art pretrained transformer models can be useful. Downside,these are complex and difficult to understand. Let alone when we combine multiple transformer models for our best attempt to win the competition…
What we did differently
No mistake about it, when we join a competition, we’re in it to win it. But we wanted to maximize learning and explainability of our approach. Therefore, where we expected many others to focus on finetuning and combining transformer models, we’ve spent much of our available time on thinking of relevant features we could create that help in understanding why our model predicts one text is more complex to read for kids than another text. We brainstormed, read the literature and checked with our friends and family with positions in education. This resulted in an impressive set of 110 features -derived from the text. These features both include readability scales from the literature – Flesh reading ease, Flesh Kinraid grade, Dale Chall Readability score – as well as other characteristics we thought might help in explaining the readability of text – sentence length, syllables per word, abbreviations, sentiment, subjectivity, scrabble points per word, etcetera
Since we think understanding the why is as important as most predictive power, we followed this approach:

Model to explain readability
We started listing potential features and started creating them in the limited time we had available for this. After this feature engineering, we estimated XGBoost models to identify the most important features and included those features in a regression model. This approach resulted in valuable insights:
- About 55% of the variance in the readability score is explained [R2] by our features
- The well-known Dale Chall readability score is by far the most predictive scale
- Many extra features we derived help in predicting and explaining readability
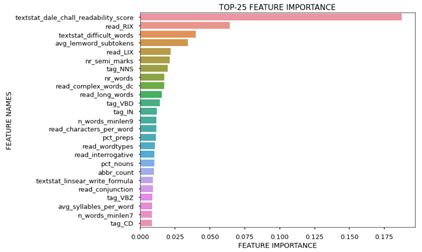
Based on these results, we can think of ways how to help publishers, teachers and students how to write texts that are easier to read.
Model to boost predictions
Yet, we were not done with a model that is doing a good job in explaining. In the second stage, we explored if transformer models (BERT, Roberta, Distilbert) could help boosting our predictions. And it did! We knew these models, pretrained on huge amounts of textual data, are state of the art and excellent in many NLP tasks. Also in our case, RSME decreased from around 0.70 to 0.47 and the explained variance [R2] increased to 79%! After hyperparameter optimization a tuned Roberta Large with some advanced sampling was our best model.
And the winner is…
[spoiler alert!] No, we didn’t win this Kaggle competition. We ended somewhere in the upper half. To be honest, quite soon we knew that our approach would not be the one that would lift our bank accounts (the winner Mathis Lucka won $20K, congrats to him!). For this type of competition, the winner spends all time and resources on building many models and combining those, squeezing every last bit of predictive power out of the train data. For example, see the approach of the runner up. It should be noted however, that the winner, Mathis Lucka did use a bunch of models and ensembled those, but also had an original approach to involve smart new data (see his Kaggle post for details).
Even though we didn’t win, we enjoyed the competition very much and we’ve learned a lot. Also, we believe that our approach – have a model to interpret to explain the why and if needed add a booster to maximize predictions is a winning approach in many real life (business) contexts. (And we believe that an approach that ensembles 10+ transformer models is not ?). Therefore, we have already started translating what we learned in this Kaggle competition into something we can help others with to get and use more readable texts. Curious what exactly? Stay tuned and you’ll find out!

Creating an overview of all my e-books, including their Google Books summary
Geplaatst op: juli 9, 2021

If, like me, you are a book lover who devours books, you are probably also familiar with the problem of bringing enough books while traveling. This is where the e-book entered my life, and it is definitely here to stay. But how to keep track of all my e-books? And how do I remember what they’re about by just seeing their title? And, the worst of all problems, how to pick the next book to read from the huge virtual pile of books?
After struggling with this for years, I finally decided it was time to spend some time to solve this problem. Why not create a Python script to list all my books, retrieve their ISBN and finally find their summary on Google Books, ending up with an Excel file containing all this information? And yes, this is as simple as it sounds! I’ve used the brilliantly simple isbntools package and combined this with the urllib package to get the summary from Google Books. Easy does it! And the result looks like this:
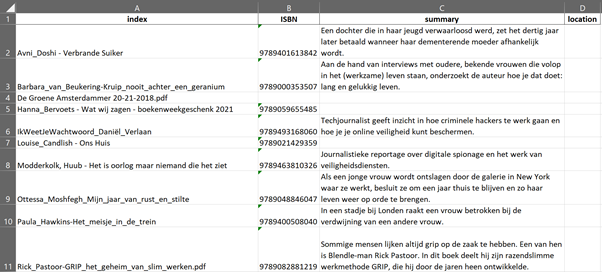
If you’re curious on which book to read next now you’ve got such a nice list of all the books you’ve already read, you should definitely checkout our fantastic book recommender to help you find your next best book.
Take a tour in the code
Initialize
Let’s start by importing packages and initializing our input information, like the link to Google Books, the file path where my books can be found, and the desired name of the Excel file we want to create.
import os, re, time
import pandas as pd
from isbntools.app import *
import urllib.request
import json
# the link where to retrieve the book summary
base_api_link = "https://www.googleapis.com/books/v1/volumes?q=isbn:"
# the directory where the books can be found and the current list of books (if exists)
bookdir = "C:/MyDocuments/Boeken" #os.getcwd()
current_books = os.path.join(bookdir, 'boekenlijst.xlsx')
Check for an existing file with books
Next we want to check if we’ve ran this script before and if there is already a list of books. If this is the case we will leave the current list untouched and will only add the new books to the file.
# check to see if there is a list with books available already
# if this file does not exist already, this script will create it automatically
if os.path.exists(current_books):
my_current_books = pd.read_excel(current_books, dtype='object')
else:
my_current_books = pd.DataFrame(columns=["index", "ISBN", "summary", "location"])
Retrieve all books
Now we walk through all folders in the given directory and only look for pdf and epub files. In my case these were the only files that I would consider to be books.
# create an empty dictionary
my_books = {}
print("-------------------------------------------------")
print("Starting to list all books (epub and pdf) in the given directory")
# create a list of all books (epub or pdf files) in the directory and all its subdirectories
# r=root, d=directories, f=files
for r, d, f in os.walk(bookdir):
for file in f:
if (file.endswith(".epub")) or (file.endswith(".pdf")):
# Remove the text _Jeanine_ 1234567891234 from the filenames
booktitle = re.sub('.epub', '', re.sub('_Jeanine _\d{13}', '', file))
booklocation = re.sub(bookdir, '', r)
my_books[booktitle] = booklocation
print("-------------------------------------------------")
print(f"Found {len(my_books.keys())} books in the given directory")
print(f"Found {len(my_current_books)} in the existing list of books")
Only process the newly found books
We don’t want to keep searching online for ISBN and summaries of the books we’ve already found before. Therefore we will remove all books from the existing file with the list of books (if this existed). If there wasn’t already such a list, nothing will happen during this step.
# only keep the books that were not already in the list
if len(my_current_books) > 0:
for d in my_current_books["index"]:
try:
del my_books[d]
except KeyError:
pass # if a key is not found, this is no problem
print("-------------------------------------------------")
print(f"There are {len(my_books.keys())} books that were not already in the list of books")
print("-------------------------------------------------\n")
Find the books online
For all the new books, we want to search for their ISBN using the book title (name of the file). Using this ISBN, we will try to find the summary of the book in Google Books.
# try to get more information on each book
i = 0
for book, location in my_books.items():
print(f"Processing: {book}, this is number {i+1} in the list")
isbn = 0
summary = ""
try:
# retrieve ISBN
isbn = isbn_from_words(book)
# retrieve book information from Google Books
if len(isbn) > 0:
with urllib.request.urlopen(base_api_link + isbn) as f:
text = f.read()
decoded_text = text.decode("utf-8")
obj = json.loads(decoded_text)
volume_info = obj["items"][0]
summary = re.sub(r"\s+", " ", volume_info["searchInfo"]["textSnippet"])
except Exception as e:
print(f"got an error when looking for {book}, the error is: {e}")
my_books[book] = {"location":location, "ISBN":isbn, "summary":summary}
i += 1
# sleep to prevent 429 time-out error in the API request to get the ISBN
time.sleep(5)
Store the list of books in Excel
Finally, we combine the existing list of books with all new books we’ve found and store this complete overview in the Excel file. We’re all done now and good to go.
# write to Excel
all_books = pd.DataFrame(data=my_books)
all_books = (all_books.T)
all_books = all_books.reset_index()
all_books = pd.concat([my_current_books, all_books])
all_books.to_excel(current_books, index=False)
It’s definitely not perfect yet, since the ISBN is matched using the title, which won’t be correct all the time, but I had a lot of fun creating this script, and I hope you’ll have fun using it!
Go to Gitlab to find the whole script and requirements.