
series: NO DATA SCIENTIST IS THE SAME! – part 8 All Python notebooks from this series are available on our Gitlab page.
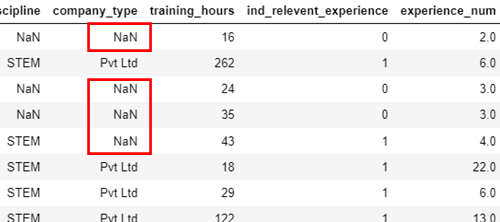
series: NO DATA SCIENTIST IS THE SAME! – part 7 All Python notebooks from this series are available on our Gitlab page.
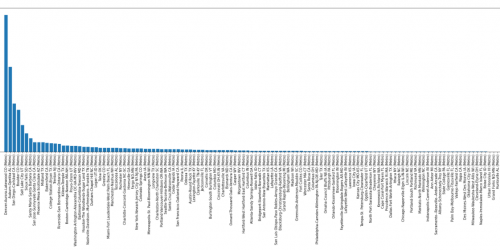
series: NO DATA SCIENTIST IS THE SAME! – part 6 All Python notebooks from this series are available on our Gitlab page.

series: NO DATA SCIENTIST IS THE SAME! – part 5 All Python notebooks from this series are available on our Gitlab page.

series: NO DATA SCIENTIST IS THE SAME! – part 4 All Python notebooks from this series are available on our Gitlab page.

series: NO DATA SCIENTIST IS THE SAME! – part 3 All Python notebooks from this series are available on our Gitlab page.
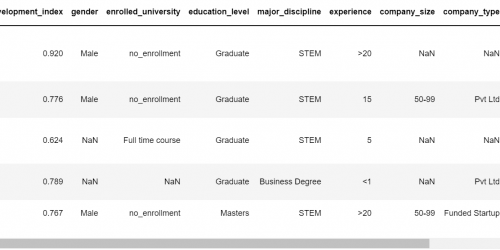
series: NO DATA SCIENTIST IS THE SAME! – part 2 All Python notebooks from this series are available on our Gitlab page.

series: NO DATA SCIENTIST IS THE SAME! – part 1 All Python notebooks from this series are available on our Gitlab page.

What did we learn from joining Kaggle’s Commonlit Readability prize? Well, next to having a lot of fun, it definitely helped us to explore the text analytics landscape even further. You can read our whole story in this article